
There is a version of the enterprise AI story already becoming conventional wisdom: the systems are getting smarter, hallucinations are getting rarer, dashboards are getting cleaner, and the path from signal to decision is getting shorter. Within a few years, every serious enterprise will run on a continuously updated, queryable model of itself — and the only remaining question is which vendor will own the model.
It is a compelling story. It is also, in the form that currently dominates, wrong in a specific and dangerous way.
The biggest risk in enterprise AI isn’t hallucination. It’s quietly wrong answers that look correct.
The failure mode we should be worrying about is not the model that confidently invents a fact. That failure is visible, embarrassing, and increasingly solvable. The failure mode to worry about is the one that looks, for six months or twelve, indistinguishable from intelligence — and is wrong at year two, after thousands of decisions have quietly compounded on top of it.
The failure mode nobody sees

Most AI systems today — whether assistant-shaped, dashboard-shaped, or workflow-shaped — deliver a single stream of output. The output is ranked, summarized, and presented with the clean typographic calm of something that has been decided.
What the user cannot see is everything that happened on the way to that calm surface. What the system chose to prioritize. What it suppressed. Which correlation it treated as a cause. Which plausible interpretation it elevated into a recommendation. Which absence of signal it failed to flag. These are not bugs. They are editorial judgments — judgments that used to be made by human managers, analysts, and reviewers, and are now being made silently, at machine speed, by systems never designed to be accountable for making them.
The consequence is not a dramatic, attributable failure. It is a slow, invisible degradation of decision quality. Here is what it actually looks like on the ground.
A field service team replaces the wrong part. A work-order assistant confidently recommends swapping a battery pack on a medical device. The recommendation reads cleanly, cites the right documents, and matches a pattern the technician has seen before. Three visits later, the real issue — a controller firmware mismatch — surfaces. The assistant had surfaced the battery pattern because the retrieval layer was denser on battery documentation than on firmware change notes. Nothing about the answer looked wrong. It just wasn’t the kind of answer anyone should have acted on without a second look.
A clinical team reads an association as evidence. A drug-information assistant surfaces a potential interaction between two medications. The phrasing is neutral, the supporting text is paraphrased from a case report, and the downstream effect is that a prescriber quietly changes their plan. The interaction is plausible — and it is not established. The system was not hallucinating. It was presenting a hypothesis with the grammar of a fact.
A commercial team kills a working feature. A customer-success model flags a usage dip and labels it “churn risk, feature-launch-correlated.” The feature in question was launched two weeks earlier. The team rolls it back. Two months later it emerges the dip was caused by a billing change on the same Tuesday — the feature was fine, and rolling it back cost the retention lift it had been creating. The model wasn’t lying. It had taken a correlation and served it as a cause.
An operations team misses the failure that already happened. A pipeline that was supposed to stream inventory telemetry stopped sending data three weeks ago. Nothing broke loudly: the dashboards kept rendering, the AI summaries kept summarizing, the week-over-week charts kept charting — against the last value the system saw. The absence of signal was, itself, the failure. And a system that has no way to flag absence will keep reporting confidence on data that is no longer being produced.
None of these look like the system failing. They look like “the market shifted” or “the customer is slipping” or “execution issues” or “bad luck.” They are, in fact, the system making small, invisible editorial mistakes — and the organization absorbing them as reality.
The category error
The category error underneath this is simple. Most AI systems treat every answer as the same kind of thing.
A factual lookup from a maintenance manual is presented with the same weight as a cross-referenced operational inference. A grounded synthesis across multiple sources appears indistinguishable from a speculative interpretation. A high-consequence, action-sensitive output sits in the same panel, with the same font and the same confidence bar, as a low-stakes reference.
The user sees one answer stream. The system knows — implicitly, somewhere in its scoring logic — these are not the same kind of answer. It just never tells you. That gap between what the system knows and what the user sees is where trust breaks down. Not catastrophically. Quietly.
AI doesn’t just inform your decisions. It quietly shapes them — without telling you.
Drawing the boundary
The fix is not a better model. It is not a larger corpus. It is not a smarter ranker. The fix is architectural — but the part of the architecture that matters is the one the user actually sees.
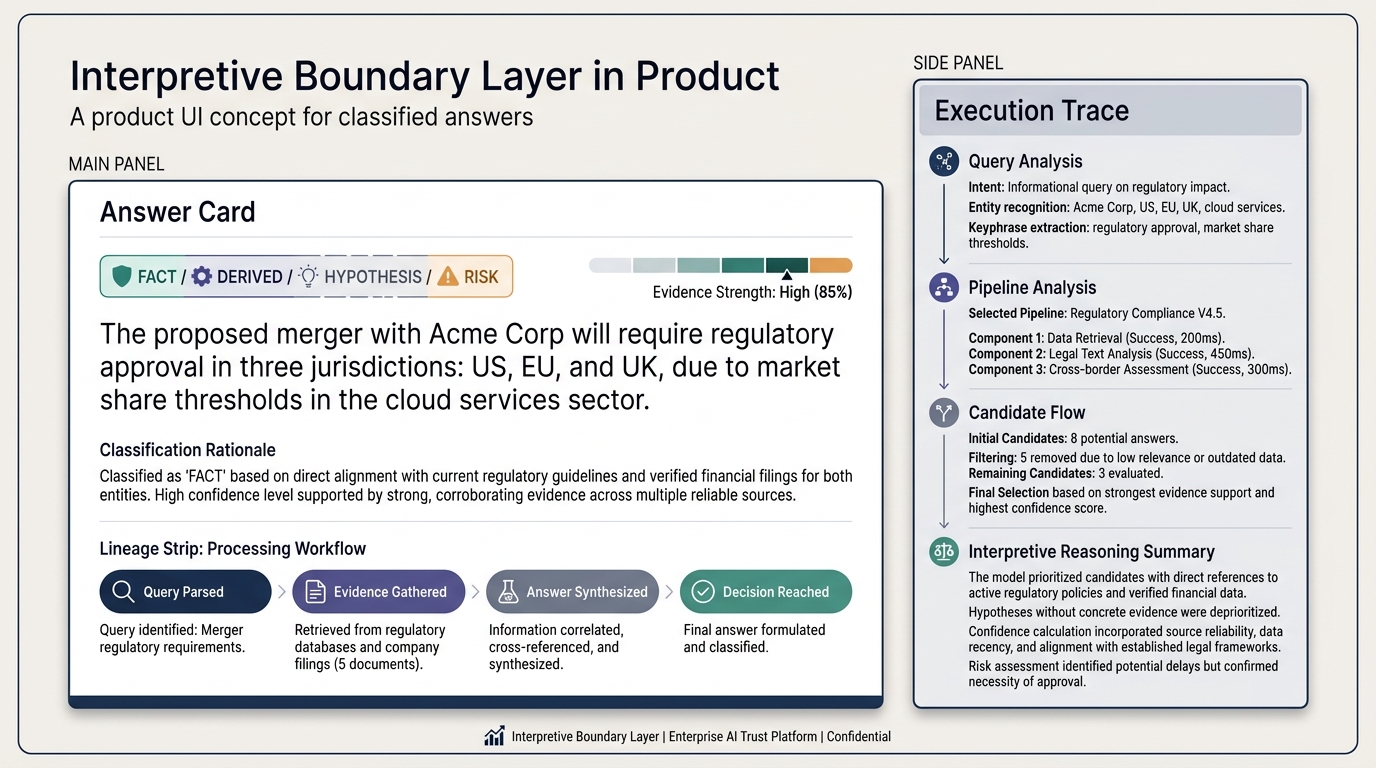
We call it the Interpretive Boundary Layer. It is the layer between what the system knows and what the system is willing to recommend you act on. Every output passes through it. Every output comes out classified.
There are two dimensions and three actionability signals. Certainty tells you how confident the system is. Impact tells you what depends on the answer. The intersection — SAFE, REVIEW, or ESCALATE — is the governance mechanism. But the deeper insight is structural: certainty is not just a classification layer. It is the third dimension of the risk equation itself.
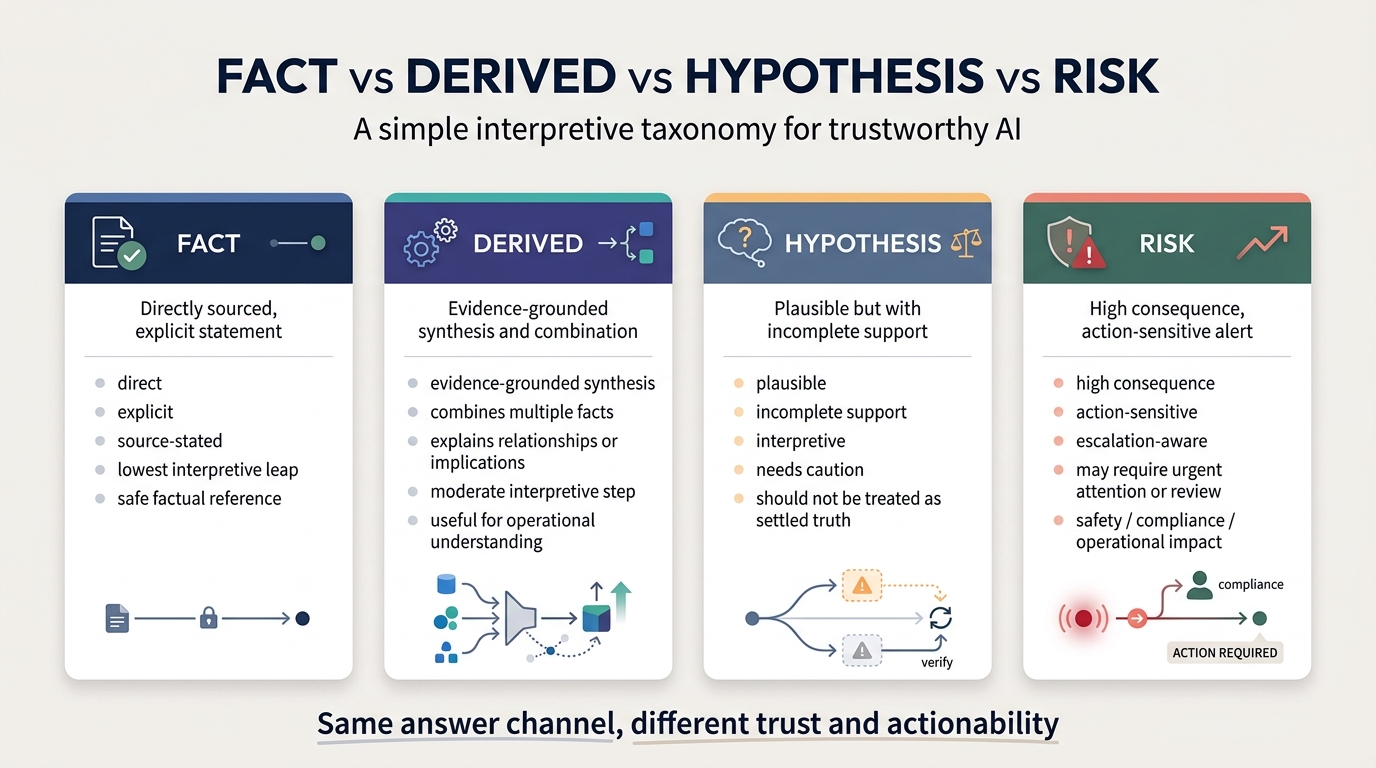
Each class has a distinct shape on the way out of the system, a distinct example, and a distinct reason it has to be called what it is.
FACT
FACT sits at the top of the certainty dimension.
What it is. A direct, evidence-stated answer. The kind that can be extracted cleanly from a specific source: a specification, a policy document, a system of record. Low interpretive leap. Safe to cite as given.
Example. “What is the maximum battery life on the HeartMate 3 pocket controller?” The answer exists in one place in the quick-reference card, it has a number on it, and a responsible system returns it with the source attached.
Why it matters. FACT is the class AI is actually good at — and the class that gets abused most often. When a system treats every answer with the calm authority that a factual lookup deserves, users start trusting synthesis and interpretation at the same level as extraction. Calling FACT by its name is half the discipline. It also, by implication, forbids the system from presenting any non-FACT answer with the same authority.
DERIVED
DERIVED is the second certainty tier — grounded but not directly extracted.
What it is. An evidence-grounded synthesis across multiple facts. Not a direct lookup, not a guess. The system has combined grounded pieces into a coherent explanation of how things relate, and it tells you it has done so. You can see the pieces it built the answer from, and you can see the shape of the reasoning.
Example. “How does the System Controller relate to the Mobile Power Unit?” There is no single document that answers this. The answer exists only as a synthesis across specs, diagrams, and service procedures — and it is legitimate, useful, and not a fact.
Why it matters. Most real operational questions land here. The single most common failure mode in enterprise AI is systems that take a derived answer and hand it back in fact-shaped packaging. That is the specific move that causes quiet, compounding error. Exposing DERIVED — as its own class, with its evidence visible — is what turns a guessing assistant into a reasoning one. This is the class most systems hide. It is also the class that does the most work in a real deployment.
HYPOTHESIS
HYPOTHESIS is the third certainty tier — plausible, not confirmed.
What it is. A plausible interpretation with incomplete support. Worth surfacing. Not safe to treat as settled truth. The system is saying, this might be what’s happening, here is why I think so, and here is what I am not sure about.
Example. “A patient on LVAD therapy is reporting neck pain; could it be related to controller cable positioning?” The documentation does not directly establish this. The pattern is real enough to surface for a clinician to evaluate — and nowhere near solid enough to be phrased as a finding.
Why it matters. HYPOTHESIS is the class that generic systems silently collapse into one of two failure modes: presented as FACT (dangerous and invisible), or suppressed entirely (wasteful, because the signal was real and useful). A hypothesis is useful precisely because it is labeled as one — it becomes a legitimate input to a human review instead of a liability hiding in a summary.
CONJECTURE
What it is. A projection from patterns where the AI extends beyond what the evidence directly supports. Not a wild guess — a structured extrapolation that the system is honest about not being able to confirm.
Example. “Other vessels in this manufacturing lot may share the same component defect — the failure pattern is consistent with a lot-level issue, but only one unit has been tested.” The pattern is real. The extension is unconfirmed. The system names both.
Why it matters. CONJECTURE is the class that used to be called RISK — but that label conflated two things. The certainty of the claim (low) and the consequence of acting on it (high) are independent properties. A conjecture about a contextual fact is harmless. A conjecture about a patient-safety trigger is dangerous. The certainty tier stays the same in both cases — what changes is the impact, and therefore the actionability. Separating these is the entire discipline of the two-dimensional model.
The Second Dimension: Impact
Certainty asks: how confident is the system? Impact asks a different question entirely: what decisions depend on this output?
A FACT about equipment installation history is INFORMATIONAL — context only, no decision gate. A FACT about a patient safety threshold is CRITICAL — even though the certainty is identical, the consequences of error are not. Certainty alone cannot govern action. Impact alone cannot govern trust. The intersection governs both.
- INFORMATIONAL — background context, no downstream decision.
- LOW-RISK — informs a non-critical workflow step.
- HIGH-RISK — affects batch disposition, CAPA, or process change.
- CRITICAL — patient safety or regulatory trigger.
The system classifies both dimensions independently, for every output, before any action is taken.
The Third Dimension
There is a deeper implication of the two-dimensional model that matters specifically to regulated enterprise.
In every GxP process — pharmaceutical manufacturing, medical device quality, clinical operations — risk is assessed as Probability of Occurrence × Impact of Occurrence. This is FMEA. This is ICH Q9. Every risk management framework in regulated industry rests on this formula.
The formula has always assumed the measurements are deterministic. A human analyst reviews the data, runs the tests, follows the SOP. The probability and impact are measured, not inferred.
AI changes that assumption. When AI assesses the probability that a failure mode will recur, the assessment may be extrapolating from an incomplete pattern. When AI assesses the impact on patient safety, it may be synthesizing across contradictory policy versions. The analysis has moved from deterministic to probabilistic — and the uncertainty of the AI’s analysis itself now affects both the P and the I.
This means the risk equation in AI-enabled systems is not P × I. It is:
Risk = Probability × Impact × Certainty of AI Analysis
The Certainty dimension spans from FACT (deterministic, factual knowledge exists) through DERIVED (built on facts, but the combination introduces uncertainty) and HYPOTHESIS (projection of prior understanding) to CONJECTURE (exploratory, possible, not certain).
This third dimension is what the Interpretive Boundary Layer measures. It is what makes AI-enabled risk assessment auditable — because the system shows not just the risk number, but how much to trust the analysis that produced it. And it creates a maturity path: as the system’s knowledge grows and evidence is verified, certainty moves toward FACT. The risk equation converges back toward deterministic. The progression is measurable.
The certainty tiers are not severity levels. They are positions on the confidence axis — and each one can appear at any point on the impact axis. A fact about background context and a fact about patient safety carry the same certainty and different impact. A conjecture about process timing and a conjecture about product quality carry the same certainty and different impact. The discipline of the Interpretive Boundary Layer is to keep these two dimensions from collapsing into one number — because the risk equation requires both, plus the certainty dimension, to be visible and independent.
Why DERIVED is the category most systems miss
If you only remember one of the four classes from this piece, remember DERIVED.
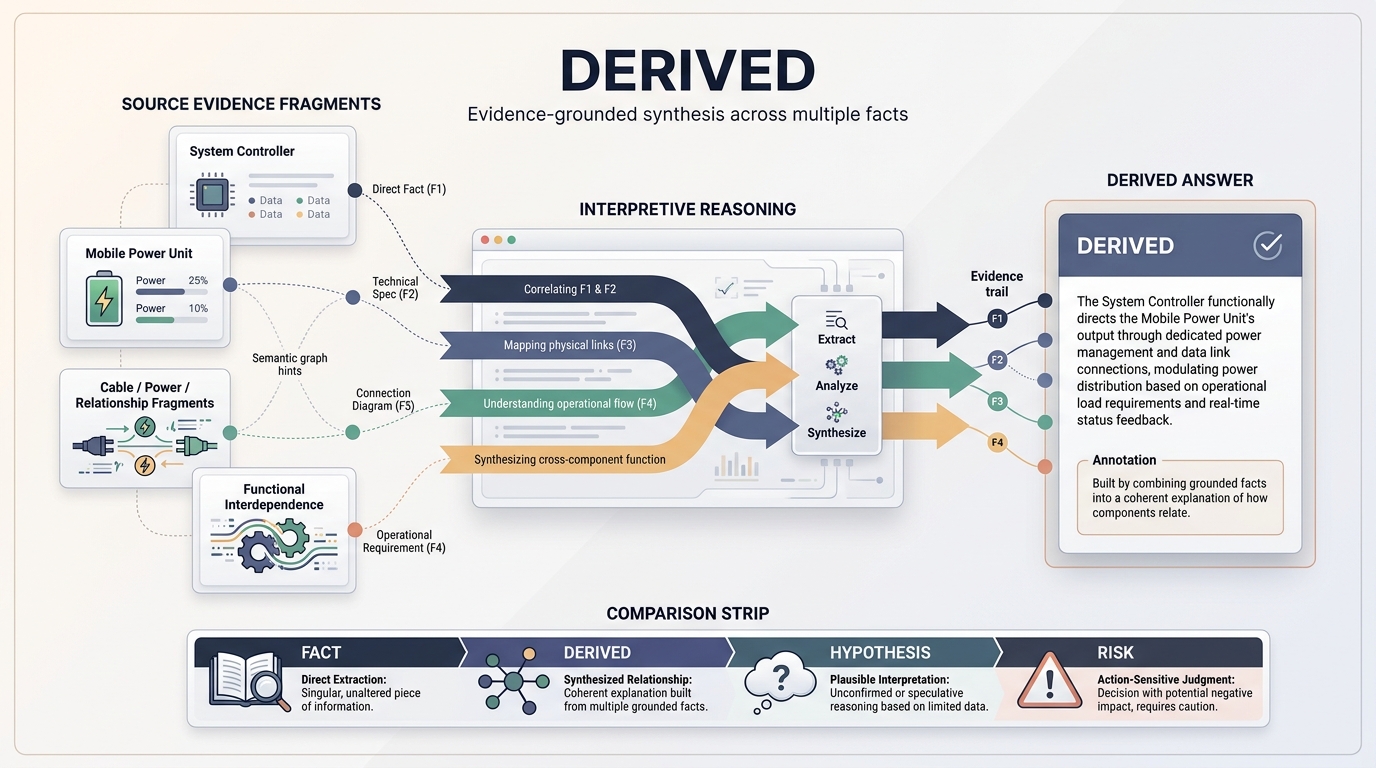
Here is a concrete case. A field technician asks, how does the System Controller relate to the Mobile Power Unit? There is no single row in any document that answers that question. There is no single paragraph to quote. The answer exists only as a synthesis — across specs, diagrams, service procedures — of how the two components functionally relate.
Most AI systems will produce that synthesis and hand it back to the user as if it were a fact. That is the failure. The answer is not a fact. It is not a hallucination either. It is a derived answer: grounded in real source material, assembled into a coherent explanation, and honest about being an assembly.
When the Interpretive Boundary Layer labels that answer as DERIVED, two things change. The user treats it appropriately — using it for operational understanding but not citing it as a primary reference. And the evidence it was built from is visible on the same surface as the answer, so the reasoning can be inspected in seconds instead of reconstructed over hours.

DERIVED is also what separates a governed system from a guessing one. A hypothesis is interpretive; a derived answer is interpretive and grounded. The difference looks subtle on paper. In a regulated environment — clinical, medtech, pharma, financial, critical infrastructure — the difference is the difference between a decision that is defensible and one that is not.
Human-in-the-Loop, on purpose
Almost every serious enterprise AI program eventually arrives at the same conclusion: some answers need a human review. This is usually labeled human-in-the-loop and treated as a policy — a line in the governance document that says “a person will check the AI before it acts.”
The trouble is that a policy without a routing rule is a bottleneck. If every answer routes to a human, the system is theatre: the human does not have time to look, so they approve on vibes and the reviewing becomes performative. If no answer routes to a human, the system is unsupervised — and the quiet failures compound. Most production AI ends up oscillating between the two, depending on workload.
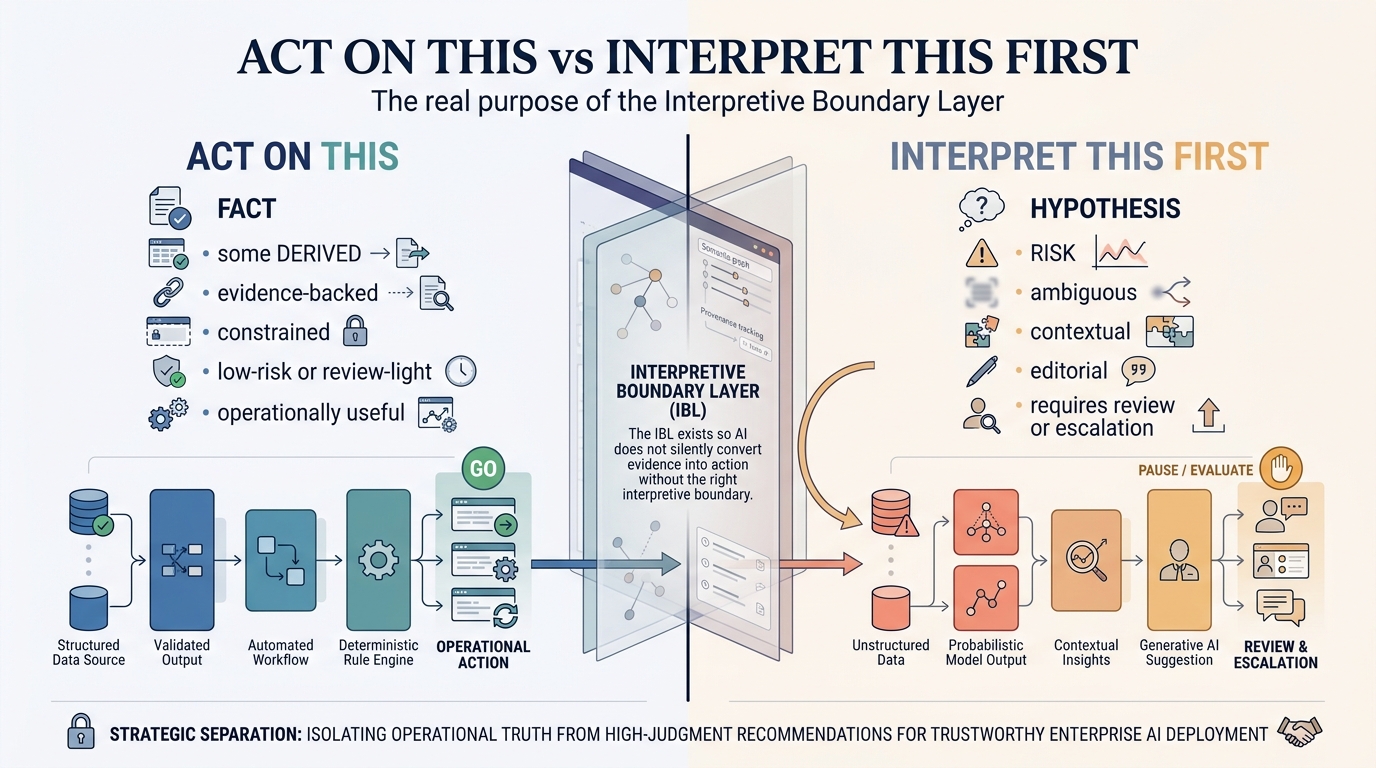
The Interpretive Boundary Layer resolves this because the answer class is the routing rule.
SAFE — routes through without human review. The certainty is high and the stakes are low. A citation is enough. Examples: FACT + INFORMATIONAL, DERIVED + LOW-RISK, HYPOTHESIS + INFORMATIONAL.
REVIEW — routes through with its reasoning attached. Either the certainty is high but the impact warrants a check, or the certainty is moderate and a real decision depends on it. The reasoning surface is exactly what makes a human review take minutes instead of hours: the reviewer reads the evidence the system used, not the answer in isolation. Examples: FACT + CRITICAL, DERIVED + HIGH-RISK, HYPOTHESIS + LOW-RISK.
ESCALATE — escalates before action. The consequence is stated plainly. The escalation path is defined. The audit trail is created at the moment the classification is assigned, not reconstructed afterward. Examples: CONJECTURE + LOW-RISK, HYPOTHESIS + HIGH-RISK, anything + CRITICAL at HYPOTHESIS or below.
The effect is that human-in-the-loop stops being a ceiling on throughput and starts being a precise, targeted routing decision. People review the answers worth reviewing, in the form worth reviewing them in. The cases that do not need them move at machine speed. The cases that do carry enough structure on arrival that a human can evaluate them without reconstructing the system’s thinking from scratch.
That is the difference between HITL as a policy and HITL as an architecture. Classification turns the second into a possibility. Two-dimensional classification makes it precise. The P × I × C formula makes it auditable.
HITL only works at scale when the system tells the human what kind of answer they are looking at.
What this changes
Once every answer is classified on both dimensions — certainty and impact — the rest of the system reorganizes around the intersection. SAFE answers flow through as operational truth, with evidence attached. REVIEW answers are routed to a human with the reasoning already laid out, so the review takes minutes instead of hours. ESCALATE answers halt before anything gets actioned, with the consequence stated plainly and the certainty gap identified.
The organization stops treating AI output as a single stream and starts treating it as a matrix of certainty and consequence — where the routing is a function of both, and the risk equation accounts for the AI’s own uncertainty as a first-class term.
The real category
The industry language for this space is still adjusting. “Governed AI.” “Trustworthy AI.” “Enterprise AI platform.” These are accurate, and not quite the right shape for what is actually being built.
The real category is decision integrity infrastructure. The right question to ask of an enterprise AI system is not how smart is it, or even how grounded is it. Those questions assume the answer stream is one thing. The right question is: does it tell you how certain its analysis is — and independently, what depends on being right? The organizations that measure both will compound decisions correctly. The ones that don’t will compound small, unmeasured uncertainties into large strategic errors.
Most AI systems automate information. The ones worth trusting govern judgment.
The Interpretive Boundary Layer is not a feature of the EnPraxis platform. It is the point of the platform. The boundary is what makes the system safe to use for decisions that actually matter.
Read next
A capability overview of how IBL fits the EnPraxis platform.