
Andrej Karpathy recently described a workflow that many of us recognize immediately because it feels both practical and inevitable.
Raw source material goes in.
An LLM incrementally compiles it into a usable knowledge base.
Concepts emerge. Summaries improve. Links form. Outputs get filed back into the system.
The knowledge base becomes more useful every time it is used.
That is a real shift.
It also points to something bigger.
The future of AI is not just better chat, better prompting, or better retrieval. It is the rise of LLM-maintained knowledge systems — and eventually, for the enterprise, governed semantic knowledge fabrics.
Karpathy is right to call out how powerful this has become. But there is also a boundary in his example that matters a great deal.
For personal research, technical exploration, and bounded team knowledge work, an LLM-compiled wiki can be incredibly effective.
For enterprises operating in regulated, high-criticality environments, it is not enough.
That is where the next architectural leap begins.
What Karpathy gets exactly right
The most important idea in the post is not retrieval.
It is compilation.
This is a subtle but profound difference.
A traditional retrieval system stores documents and tries to find relevant fragments later.
A compiled knowledge system transforms those raw documents into something more useful:
- concept pages
- summaries
- synthesized relationships
- backlinks
- visualizations
- derived artifacts
- improved structure over time
That is not just search.
That is a form of knowledge engineering.
The second important idea is that the knowledge base becomes self-improving. Every question, summary, and output can be fed back into the system and increase its value over time.
That compounding effect is real.
And it is one of the most important patterns emerging in AI right now.
Where LLM knowledge bases work beautifully
This model is especially strong when the environment is:
- bounded
- relatively small in scale
- research-oriented
- exploratory
- tolerant of approximation
- primarily read-oriented rather than action-oriented
That is why it works so well for:
- personal research repositories
- technical topic maps
- small team knowledge systems
- exploratory literature review
- code and documentation synthesis
In those contexts, markdown-based compiled knowledge is elegant. It is inspectable, editable, portable, and highly useful.
There is real product opportunity there.
Where they begin to break down
The moment you move from personal or team knowledge work into enterprise operations, the requirements change.
You no longer need just:
- useful synthesis
- fast Q&A
- decent organization
You need:
- shared meaning across functions
- versioned truth
- provenance
- authority ranking
- conflict resolution
- policy boundaries
- answerability checks
- escalation rules
- decision traceability
- and often, real-world action
A markdown wiki maintained by an LLM can appear coherent while still being structurally inconsistent. It may not know which source is authoritative. It may not know which version is current. It may not know when the available information is insufficient to answer safely. It may not know the difference between “helpful” and “allowed.”
In regulated environments, those are not edge cases.
They are the core problem.
The real enterprise question
The question is not:
Can an LLM compile knowledge into a useful wiki?
It clearly can.
The enterprise question is:
Can an AI system turn fragmented knowledge into safe, explainable, policy-aligned decisions and actions at scale?
That requires something more than a compiled markdown layer.
It requires:
- a governed business glossary
- a conceptual semantic model
- controlled mappings to standards and enterprise systems
- provenance and temporal validity
- answerability and refusal logic
- intent and specification layers
- and orchestration that can do more than generate text
That is the difference between a useful knowledge base and an operational intelligence platform.
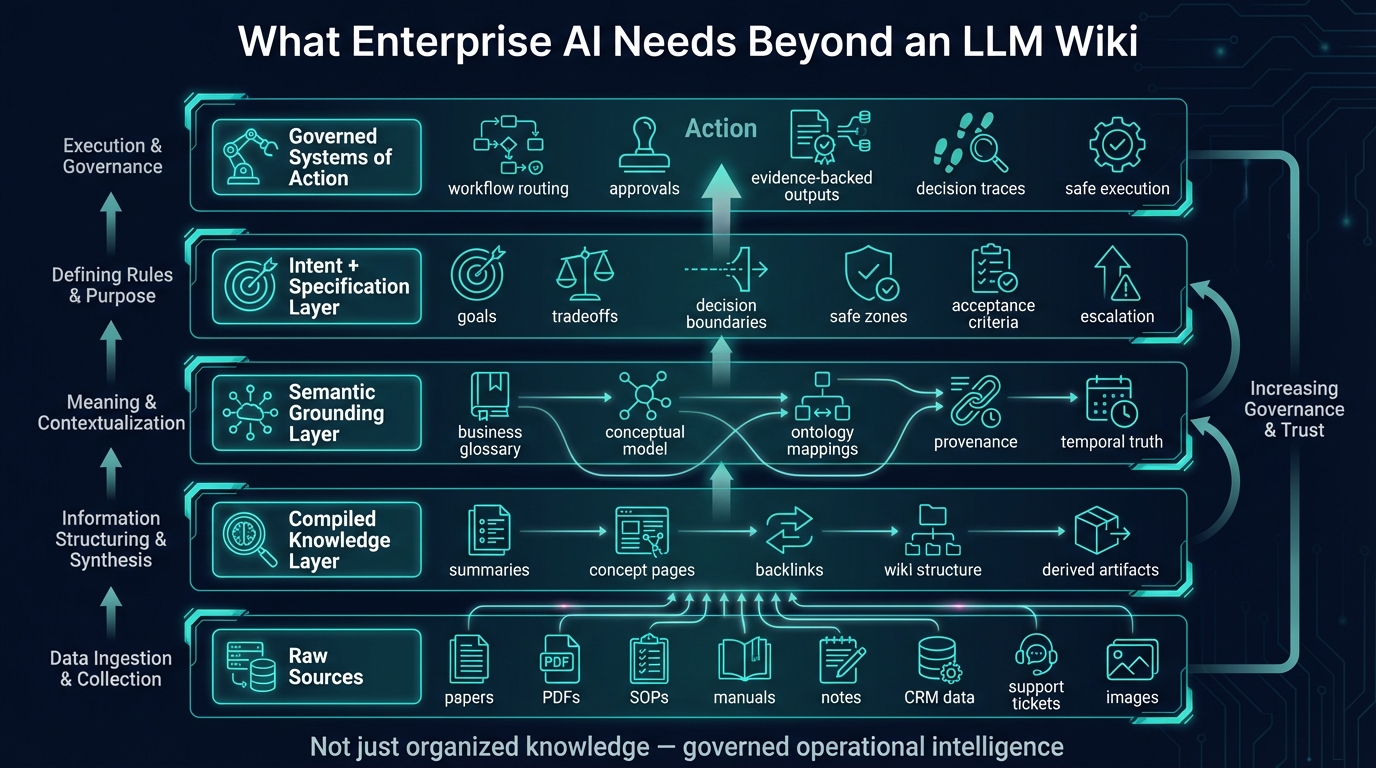
From LLM wiki to semantic knowledge fabric
At EnPraxis, we believe the right next step is not to discard this LLM knowledge base pattern.
It is to extend it into a stronger architecture.
A semantic knowledge fabric does everything a good LLM-maintained knowledge base should do:
- ingest raw content
- structure concepts
- create derived knowledge
- improve over time
- support rich Q&A
But it also adds the things enterprises actually need:
- governed business meaning
- semantic consistency across domains
- provenance and evidence
- explicit answerability
- policy and intent alignment
- executable workflows
- decision traces
- and controlled systems of action
This is the architectural difference between:
- a powerful research workflow
- and enterprise-grade AI infrastructure
Why RAG, long context, and LLM wikis are all incomplete on their own
This is why debates framed as:
- “Is RAG still needed?”
- “Do long context windows replace retrieval?”
- “Can an LLM-maintained wiki become the knowledge layer?”
…are all useful, but incomplete.
Each of these solves only part of the problem.
Long context
Useful for bounded reasoning over a small set of materials.
RAG
Useful for scaling retrieval and narrowing the search space.
LLM-maintained knowledge bases
Useful for compiling, organizing, and iteratively enriching information.
But enterprise AI needs a system that can:
- retrieve
- compile
- ground
- reason
- verify
- refuse when needed
- and act safely
That is a broader stack.
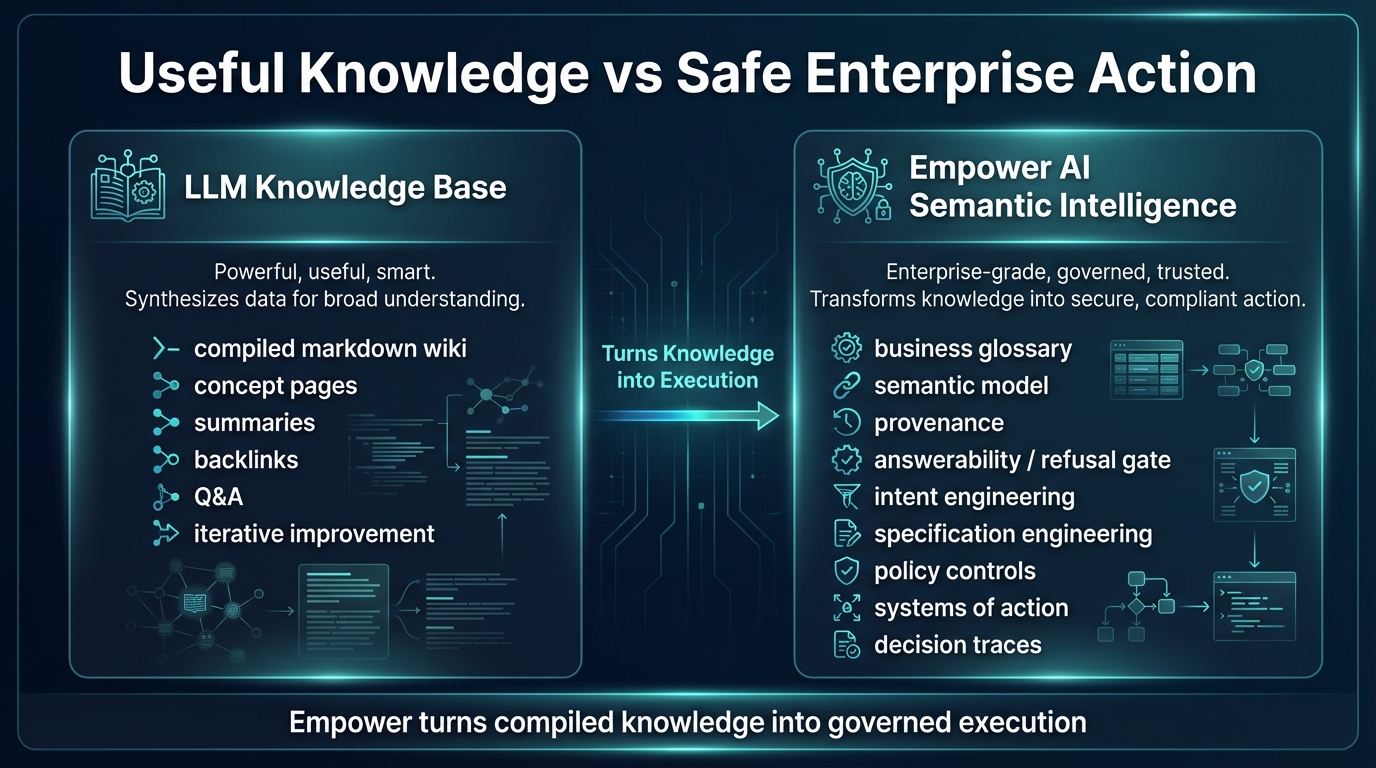
This is where Empower AI fits
Empower AI is not a “better wiki” and not a “better RAG stack.”
It is a semantic intelligence and governed execution platform.
Its foundation is the Semantic Knowledge-Operations Fabric — a governed semantic layer that turns fragmented enterprise knowledge into shared meaning, verified provenance, and executable structure.
Its role is to take the useful ideas behind:
- retrieval,
- long context,
- and LLM-compiled knowledge,
…and integrate them into something operationally trustworthy.
That means:
1. Shared enterprise meaning
Not fragmented local models, but a governed semantic foundation.
2. Provenance and temporal truth
Every claim and recommendation tied back to sources, versions, and evidence.
3. Intent and specification
Not just what the model knows, but what the organization wants, what counts as done, and what cannot be violated.
4. Systems of action
Not just answers, but workflows, approvals, routing, documentation, and traceable execution.
This is what allows AI to move from “interesting” to “production-safe” in healthcare, life sciences, MedTech, pharma, finance, and other high-criticality domains.
The right way to think about the future
Karpathy’s post points toward something important:
The future of AI is not just generation.
It is compilation + accumulation + execution.
We agree.
The difference is that for the enterprise, those systems must also be:
- governed
- explainable
- evidence-backed
- and policy-aware
So the future is not just an LLM knowledge base.
It is a governed semantic knowledge fabric that can support both:
- better thinking
- and safer action
That is the leap from a powerful personal workflow to real enterprise infrastructure.
Closing
LLM-maintained knowledge bases are real.
They are useful.
They are a genuine step forward.
But for the enterprise, especially in regulated environments, they are the beginning — not the end.
The next step is to turn compiled knowledge into governed operational intelligence.
That is where the real architecture matters.
And that is where we believe the market is heading.
An LLM wiki helps people think better.
A governed semantic knowledge fabric helps an enterprise act safely.