
Why EnPraxis
Why EnPraxis AI Wins
Enterprise AI is crowded with tools that generate text and retrieve documents. In regulated, high-stakes environments, these tools consistently fall short. Empower AI is purpose-built for the domains where generic AI fails.
The Three Moats
Empower AI's competitive position is built on three reinforcing advantages that deepen over time.
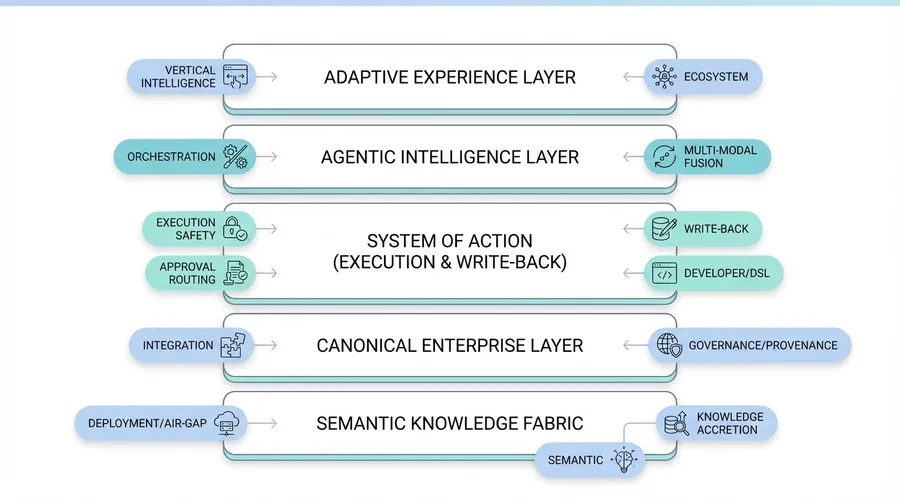
1. The Semantic Moat
Ontology-grounded knowledge graphs capture meaning, relationships, temporal truth, and provenance. This semantic foundation enables reasoning that flat retrieval systems cannot approximate, and it compounds as more knowledge is ingested.
2. The Execution Moat
Typed action registries, safe write-backs with idempotency and verification, policy gates, and rollback patterns enable production-grade autonomous execution. Competitors that remain informational cannot match the business value.
3. The Trust Moat
Governance, evaluation, and operational infrastructure built for the most demanding regulatory environments. Every decision is traced, every action is auditable, every outcome is verifiable. This trust infrastructure is the hardest moat to replicate.
These moats are mutually reinforcing. Semantic depth enables better execution. Verified execution generates trusted outcomes. Trusted outcomes feed back into richer semantic understanding.
The Core Problem with Generic AI
A Large Language Model can read everything, but it does not understand anything. It generates beautifully written maps of the world — but they are still flat ink on paper. Empower AI walks the terrain.
RAG is recall. Empower AI is reasoning.
RAG retrieves fragments. Empower AI synthesizes truth. RAG says "Here is what was said." Empower AI says "Here is what it means, why it matters, and what to do next."
LLMs are autocomplete for language.
Empower AI is a cognitive engine for knowledge — capable of reasoning, connecting, and deciding.
RAG can recall facts.
Empower AI constructs frameworks — it understands the conceptual structure behind those facts, allowing it to reason and act.
Empower AI vs. RAG/LLM Wrappers
| Dimension | RAG/LLM Wrappers | Empower AI |
|---|---|---|
| Knowledge | Flat context windows | Semantic fusion of frameworks, policies, and domain models |
| Reasoning | Pattern completion | Structured, explainable, evidence-based reasoning |
| Data | Text chunks or embeddings | Full multimodal integration |
| Actionability | Conversational only | Declarative agentic execution |
| Explainability | None or token logs | Provenance, references, audit trails |
| Speed | Weeks to months | Days |
| Maintainability | Manual reindexing | Continuous ingestion, semantic versioning |
Proof Points from the Field
One right answer — grounded in the customer's own documents, not hallucinated.
Accuracy in service workflows — without model training, powered by structured enterprise knowledge.
Deployed securely in private cloud — no data leaves, no retraining needed.
From zero to live — not months — and easily extensible across teams.
Sustainable & Responsible AI by Design
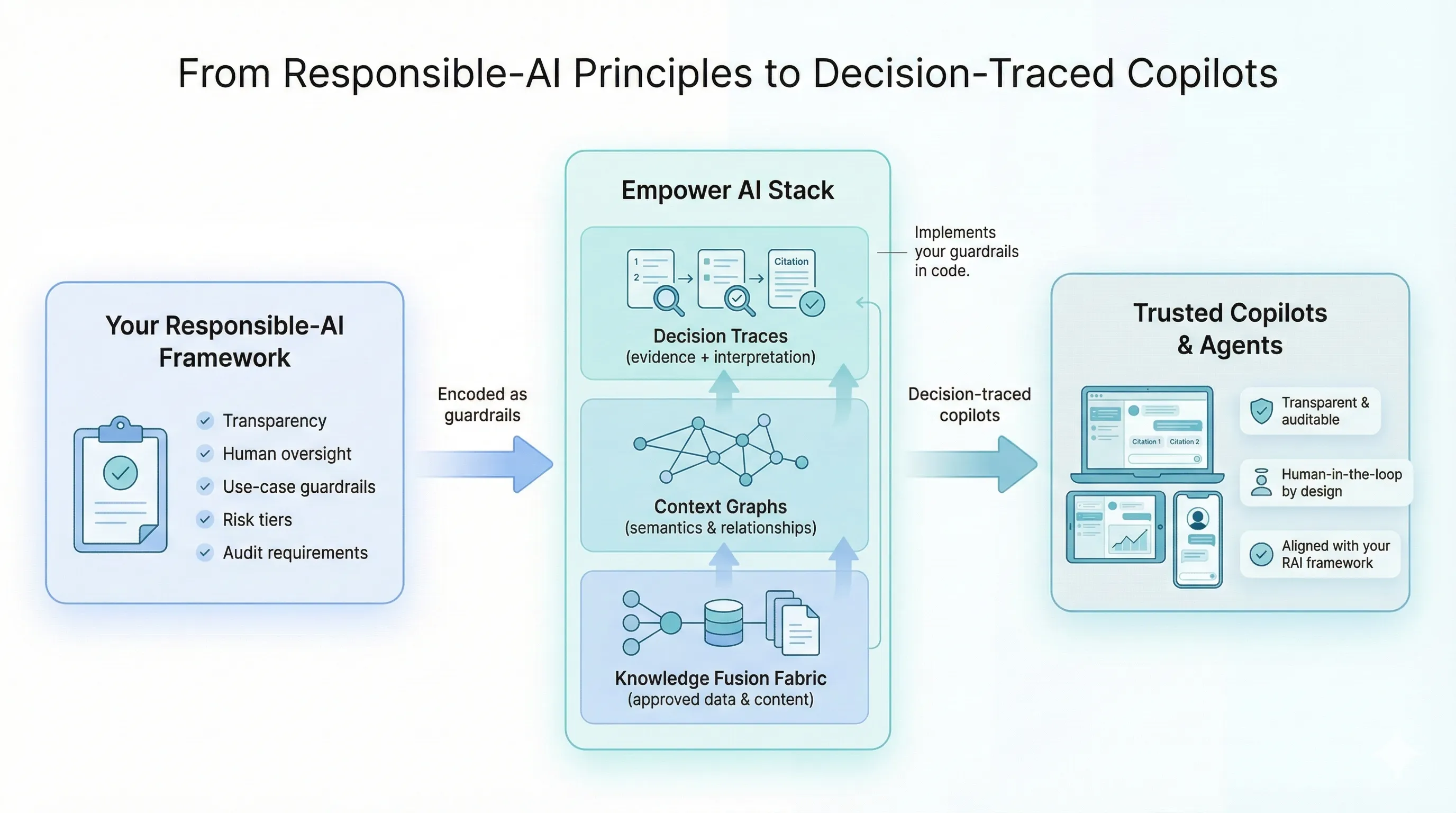
Most responsible AI programs stall at principles. Empower AI turns those principles into enforceable, measurable infrastructure.
Your RAI framework — transparency, human oversight, use-case guardrails, risk tiers, audit requirements — is encoded directly into the platform as runtime constraints. Every copilot and agent inherits these guardrails automatically, producing decision-traced outputs that are transparent, auditable, and aligned with your policies.
- Efficiency-first architecture. Small models, token budgets, and best-fit model routing — no massive retraining, no runaway compute.
- Ingest once, reuse everywhere. Knowledge is structured once and shared across copilots and agents, eliminating redundant processing.
- Responsibility as code. Guardrails, provenance tracking, and human-in-the-loop controls are enforced at the platform level — not left to individual teams.
Why Generic AI Fails in Regulated Domains
- Regulatory requirements demand traceability. Auditors need to see exactly how a decision was made. LLMs and RAG systems cannot provide this.
- Hallucinations are dangerous. In clinical, safety, and compliance contexts, a fabricated answer can cause real harm.
- Domain complexity exceeds context windows. Enterprise decisions require synthesizing information across dozens of documents, systems, and data types.
- Actions must be governed. Enterprise AI must execute within policy bounds, with approvals, verification, and rollback capability.

Detailed Comparison Matrix
| Capability | LLM + RAG | Copilots | Custom ML | Empower AI |
|---|---|---|---|---|
| Knowledge | Text fragments | Vendor-scoped | Curated sets | Ontology-grounded graph |
| Reasoning | Pattern matching | Vendor suggestions | Statistical inference | Causal, multi-hop |
| Context | One query window | App-bounded | Model-bounded | Persistent semantic fusion fabric |
| Output | Fluent text | App actions | Predictions | Structured insight + actions |
| Trust | Probabilistic | Vendor-dependent | Model-dependent | Deterministic provenance |
| Actionability | Informational | Within vendor | Custom integration | Governed execution |
| Speed | Weeks-months | Vendor rollout | Months-years | Days |
Ready to see it in action?
Request a demo to explore how Empower AI can transform your enterprise.